Simple Site - Extensions
Adding further functionality
This project will take a small set of JSON files, process them and produce a formatted set of html webpages. So the next question is, what other processing functions can be added to the system to allow ones GitHub project to host additional tools or even turn a project into a simple virtual research environment.
New Opportunities
What jobs could require consistent processing of simple files of text, or numbers, and then present formatted results in image viewers, graphs, maps, flow charts, etc?
There are lots of great pieces of software out there, so this project is intended to make use of open source libraries rather than creating new ones.
The main question here is, how can researchers, who do not have their own web server, or sufficient coding skills gain access to their own data processing and presentation system?
How it works
As has already been explained, the page JSON file includes two variables that can be used to indicate the inclusion of a page extension.
Simply, the class variable indicates what type of extension should be included and the file variable indicates the name of the file that includes any required extra data. For example, two classes currently available are:
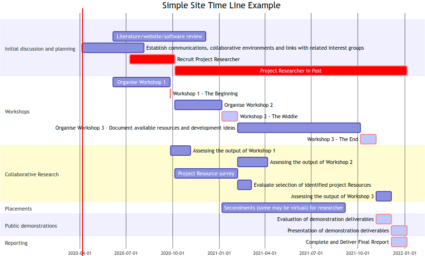
- The timeline class, which can be used to include a formatted Gantt Chart, using the Mermaid library, to display a simple project timeline.
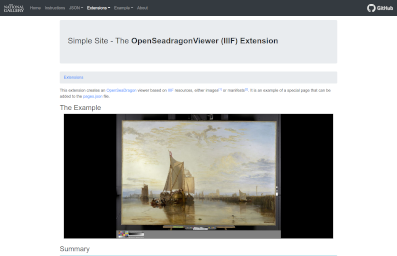
- The mirador class, which can be used to include an IIIF images viewer called Mirador, to organise and present high resolution images, which are already hosted elsewhere on the web.
Positioning the extension content
By default all extension content will be automatically added below the details given in the content or content right fields. If one would like the content to appear before of even embedded within the details provided by content or content right then it can be positioned by simply adding [##] at the appropriate position. The system will automatically replace [##] with the chosen extension content.
Examples Gallery




Display the full code used to define this page.
Page JSON Object
{
"parent": "documentation",
"class": "",
"file": "",
"title": "Simple Site - <b>Extensions</b>",
"content": "<h3>Adding further functionality</h3>\r\n<p>This project will take a small set of JSON files, process them and produce a formatted set of html webpages. So the next question is, what other processing functions can be added to the system to allow ones GitHub project to host additional tools or even turn a project into a simple virtual research environment.</p>\r\n\r\n<div class=\"alert alert-info\" role=\"alert\"><h4 class=\"alert-heading\">New Opportunities</h4><p>What jobs could require consistent processing of simple files of text, or numbers, and then present formatted results in image viewers, graphs, maps, flow charts, etc?</p><p>There are lots of great pieces of software out there, so this project is intended to make use of open source libraries rather than creating new ones.</p><p>The main question here is, <b>how can researchers, who do not have their own web server, or sufficient coding skills gain access to their own data processing and presentation system?</b></p></div>\r\n\r\n<h3>How it works</h3>\r\n<p>As has already been explained, the [page|pages.json.html] JSON file includes two variables that can be used to indicate the inclusion of a page extension.</p>\r\n\r\n<figure>\r\n\t\t<pre style=\"overflow: hidden;border: 2px solid black;padding: 10px;\">\r\n<code>... \r\n \"<b>class</b>\": [\"Indicates which project extension to use\"],\r\n \"<b>file</b>\": [\"Indicates the file in which any required extra data can be found\"],\r\n...\r\n</code></pre><figcaption class=\"figure-caption\">Extension variables included in the [pages.json|pages.json.html] page object.</figcaption>\r\n</figure>\r\n<p>Simply, the <b>class</b> variable indicates what type of extension should be included and the <b>file</b> variable indicates the name of the file that includes any required extra data. For example, two classes currently available are:</p>\r\n<ul>\r\n<li>The [timeline|timeline.html] class, which can be used to include a formatted [Gantt Chart|https://en.wikipedia.org/wiki/Gantt_chart], using the [Mermaid|https://mermaid-js.github.io/mermaid/#/] library, to display a simple project timeline.</li>\r\n<li>The [mirador|IIIF%20viewer.html] class, which can be used to include an [IIIF|https://iiif.io/] images viewer called [Mirador|https://projectmirador.org/], to organise and present high resolution images, which are already hosted elsewhere on the web.</li>\r\n</ul>\r\n<h4>Positioning the extension content</h4>\r\n<p>By default all extension content will be automatically added below the details given in the <b>content</b> or <b>content right</b> fields. If one would like the content to appear before of even embedded within the details provided by <b>content</b> or <b>content right</b> then it can be positioned by simply adding <b>[##]</b> at the appropriate position. The system will automatically replace <b>[##]</b> with the chosen extension content.</p>\r\n\r\n<h3>Examples Gallery</h3>\r\n\r\n\r\n <div class=\"row text-center text-lg-left\">\r\n <div class=\"col-lg-3 col-md-4 col-6\">\r\n <a href=\"timeline.html\" class=\"d-block mb-4 h-100\">\r\n <img class=\"img-fluid img-thumbnail\" src=\"graphics/timeline_thumb.png\" alt=\"\">\r\n </a>\r\n </div>\r\n <div class=\"col-lg-3 col-md-4 col-6\">\r\n <a href=\"mirador-viewer.html\" class=\"d-block mb-4 h-100\">\r\n <img class=\"img-fluid img-thumbnail\" src=\"graphics/mirador_thumb.png\" alt=\"\">\r\n </a>\r\n </div> \r\n <div class=\"col-lg-3 col-md-4 col-6\">\r\n <a href=\"panel-truck-viewer.html\" class=\"d-block mb-4 h-100\">\r\n <img class=\"img-fluid img-thumbnail\" src=\"graphics/panel-truck_thumb.png\" alt=\"\">\r\n </a>\r\n </div> \r\n \r\n <div class=\"col-lg-3 col-md-4 col-6\">\r\n <a href=\"curtain-viewer.html\" class=\"d-block mb-4 h-100\">\r\n <img class=\"img-fluid img-thumbnail\" src=\"graphics/curtain-viewer_thumb.png\" alt=\"\">\r\n </a>\r\n </div> \r\n <div class=\"col-lg-3 col-md-4 col-6\">\r\n <a href=\"openseadragon-viewer.html\" class=\"d-block mb-4 h-100\">\r\n <img class=\"img-fluid img-thumbnail\" src=\"graphics/openseadragon_thumb.png\" alt=\"\">\r\n </a>\r\n </div> \r\n <div class=\"col-lg-3 col-md-4 col-6\">\r\n <a href=\"lists.html\" class=\"d-block mb-4 h-100\">\r\n <img class=\"img-fluid img-thumbnail\" src=\"graphics/lists_thumb.png\" alt=\"\">\r\n </a>\r\n </div> \r\n </div>",
"content right": "",
"copy": false,
"displaycode": true
}